总结分三大部分:html、css和javascript,每部分再分成两个子部分,分别是基础知识和记忆知识。
- 基础知识指前端开发必须会的东西,比如页面渲染方式、js基础语法等。
- 记忆知识指一些单纯背背就可以的知识,忘记的话可以查,但是免试官可能喜欢问(哭笑
Html相关
浏览器内核 [记忆知识]
浏览器内核又可以分为渲染引擎和js引擎两部分,后来js引擎越来越独立,内核也就更倾向于指渲染引擎本身的部分。目前常见的内核引擎有Trident、Gecko、Blink、Webkit四种。
-
Trident
- 微软开发的内核,从IE4一直用到现在IE11。因为有过一段时间比较牛逼,拖更了很久,导致其与W3C标准脱节,加上大量BUG和安全问题都没有解决,导致现在很多用户用IE是为了下载其它浏览器。现在Win10最新的Edge浏览器已经不用这个内核,而是用自己开发的edge内核。
-
Gecko
- 是一个开源内核,源自于古时候与ie对抗的Netscape。目前前端开发经常使用的Firefox浏览器就使用Gecko内核。另外这个内核还兼容很多平台,各种系统都能用。
-
Webkit
- 苹果公司开发的内核,早起也被chrome使用。后来因为chrome火了,导致大家以为webkit是谷歌弄得,哈哈。其前身是KDE的KHTML。
-
Blink
- 谷歌Chrome目前使用的内核,其前身是Chromium,而Chromium的前身就是webkit。因为商业竞争等各种关系,谷歌弄出了blink与苹果分道扬镳。
参考来源 :
[1] 主流浏览器内核介绍(前端开发值得了解的浏览器内核历史)
DOM操作 [基础知识]
DOM的全称是Document Object Module, 文档对象模型,他是独立于语言而存在的。
-
根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
-
整个文档是一个文档节点
-
每个 HTML 元素是元素节点
-
HTML 元素内的文本是文本节点
-
每个 HTML 属性是属性节点
-
注释是注释节点
-
window.documnet是浏览器为我们提供的可以操作dom的接口。
-
随着Html5标准的推广,很多大家常用的JQuery的一些方法与浏览器原生提供的方法差别不大了,可以多了解一下原生的API。
参考来源 :
[2] 理解DOM结构
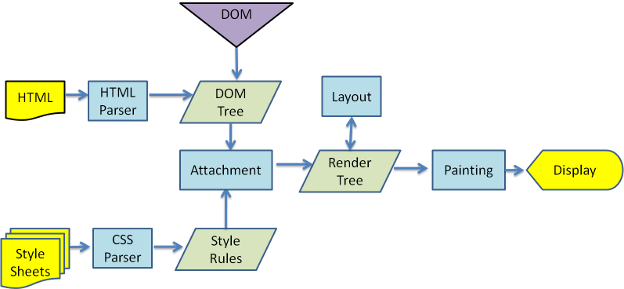
DOM渲染方式 [基础知识]
浏览器在读取Html文档后,首先会构建DOM树,随后构建渲染树,最后渲染并显示。
分词算法
算法的输出是HTML符号。算法可以用状态机来描述。 每一个状态从输入流中消费一个或多个字符,并根据它们更新下一状态。决策受当前符号状态和树的构建状态影响。这意味着同样的字符可能会产生不同的结果,取决于当前的状态。算法太复杂,我们用一个例子来看看它的原理。
基础示例,分析下面的标签:
<html>
<body>
Hello world
</body>
</html>
初始状态是”Data state”,当遇到”<“时状态改为“Tag open state”。吃掉”a-z”字符组成的符号后产生了”Start tag token”,状态变更为“Tag name state”。我们一直保持此状态,直到遇到”>”。每个字符都被追加到新的符号名上。在我们的例子中,解出的符号就是”html”。
当碰到”>”时,当前符号完成,状态改回“Data state”。”
”标签将会以同样的方式处理。现在”html”与”body”标签都完成了,我们回到“Data state”状态。吃掉”H”(”Hello world”第一个字母)时会产生一个字符符号,直到碰到””的”<“符号,我们就完成了一个字符符号”Hello world”。
现在我们回到“Tag open state”状态。吃掉下一个输入”/”时会产生一个”end tag token”并变更为“Tag name state”状态。同样,此状态保持到我们碰到”>”时。这时新标签符号完成,我们又回到“Data state”。同样”